[Kafka 기초 학습] 카프카 기초 개념 5 - 프로듀서 이해 및 실습 진행
지난 시간에는 메시지와 메시지 포맷 그리고 파티셔닝에 대해서 알아보았다.
이번 글에서는 프로듀서와 컨슈머에 대해 각각 알아보고 어떻게 작동하는지를 찾아보고 또 실습을 할 것이다.
목표
1. 프로듀서에 대해 깊이 이해한다.
2. 프로듀서의 다양한 옵션을 사용해 실제로 실습한다.
0. 들어가기 전에

필자가 Kafka 공부를 시작하면서 구성한 mini pc 와docker를 이용한 구성도이다.
이를 보고 이제 producer와 consumer가 어떻게 어디에 들어가서 작동하는지를 알아볼 것이다.
프로듀서와 컨슈머는 한글로 번역하면 생성자와 소비자이다.
우리는 계속 레코드를 topic내 파티션들에 쌓고 이곳에 메시지 혹은 레코드를 쌓고 이를 읽는 것을 보았다.
프로듀서(producer)란 그래서 뭐라고 설명하면 될까?
confluent에서는 Kafka Producer를 다음와 같이 정의한다.
An Apache Kafka® Producer is a client application that publishes (writes) events to a Kafka cluster.
출처 : https://docs.confluent.io/platform/current/clients/producer.html
카프카 클러스터에 이벤트를 발행하는 클라이언트 어플리케이션이라고 한다.
1. 프로듀서 구조와 동작 방식
필자가 이전에는 내부의 docker, 클러스터, 브로커, 파티션, 세그먼트에 대해서 그렸다.
이에 더해서 이번 그림에서는 프로듀서를 추가하였다.
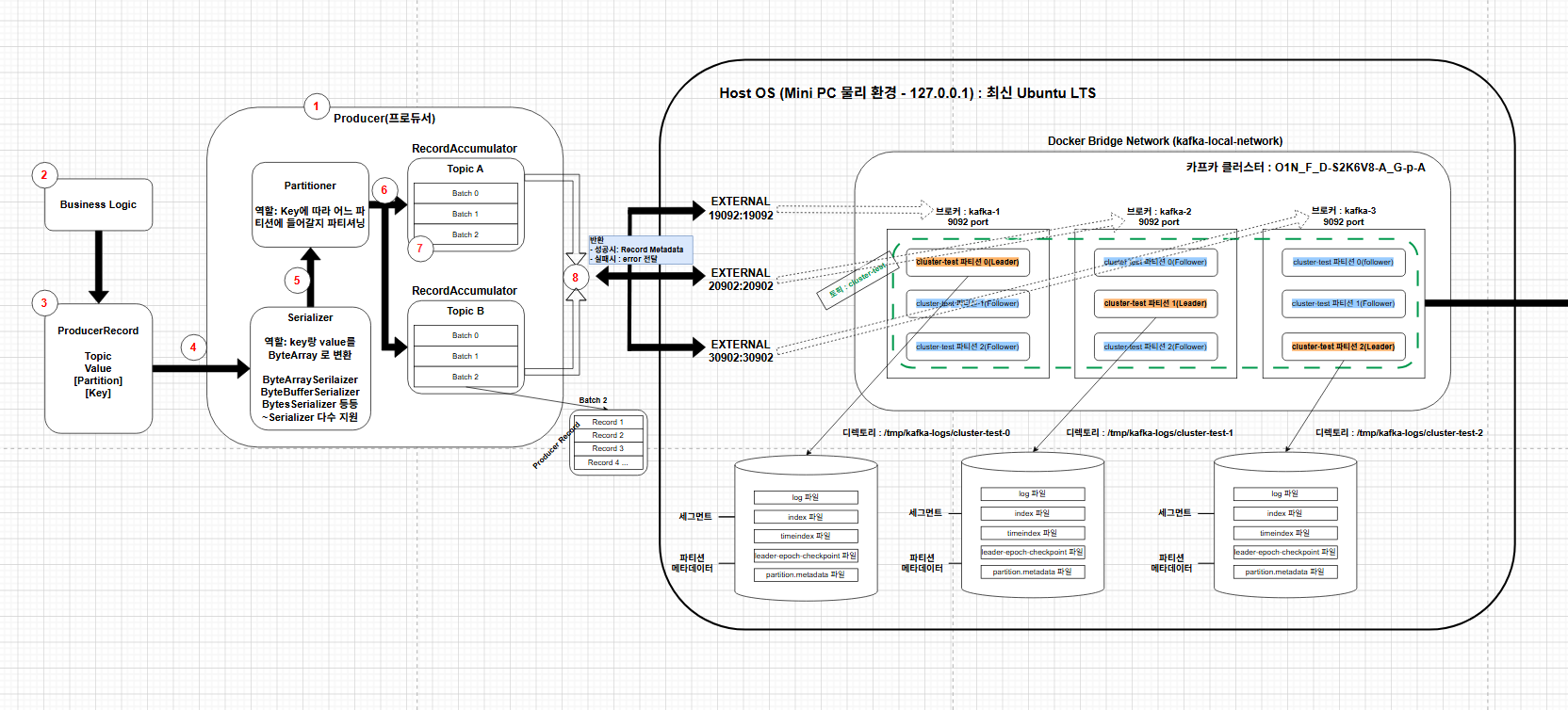
프로듀서 부분을 확대해 보겠다.

흐름을 설명하기 위해서 1에서 9번까지 번호를 매겼다.
해당 부분을 Java 코드의 설명을 곁들여 순서대로 설명을 하겠다. 물론 Java만을 지원하는게 아닌 여러 코드로 지원을 하니 궁금하면 찾아보자!
1.1) 프로듀서 생성
말 그대로 프로듀서를 생성한다.
코드에 보면 new KafkaProducer라는 코드를 통해 생성한다.
원본은 해당 코드를 참고하길 바란다.(KafkaProducer.java)
코드를 잠시 들여다보자.
/*
출처 : https://github.com/a0x8o/kafka/blob/master/clients/src/main/java/org/apache/kafka/clients/producer/KafkaProducer.java
모든 권한은 Apache 재단에 있음을 공지함!
*/
public class KafkaProducer<K, V> implements Producer<K, V> {
private final Logger log;
private static final String JMX_PREFIX = "kafka.producer";
public static final String NETWORK_THREAD_PREFIX = "kafka-producer-network-thread";
public static final String PRODUCER_METRIC_GROUP_NAME = "producer-metrics";
private final String clientId;
// Visible for testing
final Metrics metrics;
private final KafkaProducerMetrics producerMetrics;
private final Partitioner partitioner;
private final int maxRequestSize;
private final long totalMemorySize;
private final ProducerMetadata metadata;
private final RecordAccumulator accumulator;
private final Sender sender;
private final Thread ioThread;
private final CompressionType compressionType;
private final Sensor errors;
private final Time time;
private final Serializer<K> keySerializer;
private final Serializer<V> valueSerializer;
private final ProducerConfig producerConfig;
private final long maxBlockTimeMs;
private final boolean partitionerIgnoreKeys;
private final ProducerInterceptors<K, V> interceptors;
private final ApiVersions apiVersions;
private final TransactionManager transactionManager;
/**
* A producer is instantiated by providing a set of key-value pairs as configuration. Valid configuration strings
* are documented <a href="http://kafka.apache.org/documentation.html#producerconfigs">here</a>. Values can be
* either strings or Objects of the appropriate type (for example a numeric configuration would accept either the
* string "42" or the integer 42).
* <p>
* Note: after creating a {@code KafkaProducer} you must always {@link #close()} it to avoid resource leaks.
* @param configs The producer configs
*
*/
public KafkaProducer(final Map<String, Object> configs) {
this(configs, null, null);
}
/**
여러가지 멤버변수가 보인다. 이어서 예기한 Partioner, RecordAccumulator, Serializer가 눈에 보인다.
또 Sender도 보이고 Thread, ProducerMedata도 보인다.
간단히 정리하고 가자.
ProducerMetadata
카프카 클러스터의 최신 상태 정보를 캐싱하고 관리하는 '지도' 역할
- 분산 환경에서는 메시지를 보낼 때 대상 토픽의 파티션이 몇 개인지, 그리고 해당 파티션의 리더(Leader) 브로커가 클러스터 내의 어느 노드인지 확인
- send()를 호출하면 해당 메타데이터를 참조하여 라우팅 경로를 설정
- 클라이언트가 직접 라우팅 테이블을 들고 있어 서버 측의 병목을 줄이는 분산 시스템의 핵심 원리
여기서 라우팅 경로를 설정한다는 말이 무엇인가?
분산 환경에서 '라우팅 경로를 설정한다' 라는 말은 현재 클라이언트인 Producer가 메시지를 보낼 때
최종 목적지인 특정 서버 노드의 정확한 물리적 주소(IP와 Port)를 스스로 찾아내어 직접 TCP 연결을 맺는 일련의 과정을 의미한다.
그리고 어떻게 해서 이것이 서버 측의 병목을 줄이는 분산 시스템 핵심 원리인가?
잘 생각해보자. 지금 이상하게 메시지를 보내는 주체가 메시지를 받을 곳의 정보를 가지고 있다.
일반적인 Spring 서버를 생각하면 메시지가 어떻게 날아오는지 보고 Filter에서 거르건 메시지를 보고 체크해서 없애건 뭔가 그런데...
Producer에서는 뭔가 직접 서버를 확장짓고 서버의 어느 토픽의 파티션에 보낼지 조차도 미리 정해놓는다.
그렇기 때문에 이미 목적지를 지정하는 작업을 producer에서 했기 때문에 서버측의 병목을 줄인다~ 하고 표현이 가능하다!
Sender
실제로 카프카 브로커와의 통신을 담당하는 Runnable 구현
- 메인 비즈니스 스레드가 RecordAccumulator라는 메모리 버퍼에 메시지를 차곡차곡 쌓아두면, Sender는 이 버퍼를 지속적으로 확인한다.
- 이후 목적지 브로커가 같은 메시지들을 배치(Batch) 형태로 묶어서 한 번에 전송
- batch.size, linger.ms 튜닝할 때 이 설정들이 직접적으로 제어하는 대상이 바로 Sender의 배치 생성 및 전송 주기!
Thread
Sender 객체를 실행시키는 실제 백그라운드 스레드
- 카프카 프로듀서는 기본적으로 스레드 세이프(Thread-safe)하며, 내부적으로 Java NIO를 활용하여 Non-blocking으로 동작
- 수십, 수백 개의 Spring Boot 톰캣 요청 스레드가 동시에 send()를 호출해도, 실제 네트워크 전송은 이 단일 ioThread가 전담하는데 이를 통해 애플리케이션의 비즈니스 로직 스레드와 네트워크 I/O 스레드가 완벽히 격리!
1.2) 비즈니스 로직의 구현
Kafka 에 메시지를 보내기 위해서는 외부에서 어떤 일이 일어나야 할 것이다. 그리고 그 일을 받아서 데이터로 가공했다고 하자.
예를 들어서 IoT기기의 온도를 측정했다고 하자. 그러면 그 정보를 ProducerRecord로 생성한다.
1.3) ProducerRecord
ProducerRecord는 topic, record, 값 혹은 key정보들이 담겨 있다.
Java 코드를 바탕으로 어떻게 담는지 대충 보자.
Properties p = new Properties();
p.put("bootstrap.servers", "broker1:9092,broker2:9092");
p.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
p.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer");
p.put("schema.registry.url", "http://registry:8081");
p.put("client.id", "payments-prod-v1");
// Note: enable.idempotence=true is the default since Kafka 3.0+
p.put("acks", "all"); // Ensures durability with in-sync replicas
try (Producer<String, GenericRecord> producer = new KafkaProducer<>(p)) {
ProducerRecord<String, GenericRecord> rec = new ProducerRecord<>("payments", "user-42", value);
producer.send(rec, (md, ex) -> {
if (ex != null) {
// log error with client.id, topic, partition
} else {
// md.topic(), md.partition(), md.offset()
}
});
producer.flush(); // optional if you close soon after
}
출처 : https://www.conduktor.io/glossary/kafka-producers
참고하고 있는 사이트에서 긁어왔는데, ProducerRecord라는 것이 보인다.
ProducerRecord 를 만들기 전에 Properties 도 물론 설정할 수 있다. 해당 서버는 어디의 브로커에 갈것이고, 어떤 serializer 를 써야할지, acks 설정은 어떻게 할 것인지 말이다.
원하는 값을 넣었으면 이것을 전송한다. 그러면 가장 먼저 Producer의 Serializer 가 ProducerRecord의 key와 value를 Byte Array 형식으로 변환한다.
1.4 ~ 1.5) 전송시 + Serializer
필자도 공부를 하면서 잠시 헷갈렸는데 여기서 오해하면 안되는 점이 있다.
Byte Array라고 해서 kafka가 지원하는 구현체의 Byte Array를 말하는것이 아니다.

카프카 네트워크를 타고 브로커로 넘어가는 최종 형태는 무조건 바이트 배열이다.
모든 Serializer의 궁극적인 목적은 Java 객체를 바이트 배열로 바꾸는 것이다.
하지만 '무엇'을 바이트로 바꿀지는 개발자가 정해야 한다!
위의 사진 밑에 첨부한 Java docs주소를 보고 알맞은 것을 사용하면 된다.
Producer의 serializer가 client application 에게서 받은 byte array 로 된 정보를 잘 직렬화해서 Partitioner에게 전달한다.
물론 그 전에 담기는 Record들에 대해서 압축도 할 수 있고 여러 설정이 가능하다. (이전 글 참고)
1.6) Partitioner
Serializer 로 잘 변환을 했으니 이 내부의 Key값을 Partitioner가 보고 어느 Partition으로 갈 지 정한다.
그리고 Kafka Cluster에 전송하기 전에 RecordAccumulator에 쌓는다.
실제 코드를 보고 싶으면 해당 링크를 참고하길 바란다. (RecordAccumulator Java Docs)
RecordAccumulator에 저장하기 전에 Record의 Serialized Size를 검사한다. 설정값에 벗어나면 Exception이 발생한다.
문제가 없으면 RecordAccumulator의 append() 를 이용해 저장한다.
append가 호출되면 batches에 추가될 Record에 해당하는 TopicPartition의 Deque를 찾는다.
Deque<ProducerBatch> dq = topicInfo.batches.computeIfAbsent(
effectivePartition, k -> new ArrayDeque<>()
);
여유 공간이 있으면 해당 RecordBatch에 Record를 추가하고, 여유 공간이 없으면 새로운 RecordBatch를 생성해서 Last쪽으로 저장한다.
// 기존 공간에 append
RecordAppendResult appendResult = tryAppend(
timestamp, key, value, headers, callbacks, dq, nowMs
);
// 새 공간에 append
RecordAppendResult appendResult = appendNewBatch(
topic, effectivePartition, dq, timestamp, key, value, headers, callbacks, buffer, nowMs
);
Queue를 사용하지 않고 Deque가 사용된 이유는 append() 시에 가장 최근에 들어간 RecordBatch를 꺼내서 봐야 하기 때문이라고 한다.
왜 꺼내서 봐야하냐고? RecordBatch에 새로운 메시지를 추가할 수 있는 여유 공간이 남아있는지 확인하기 위해서이다.!
다음의 그림이 이 이유를 설명한다. Naver 에서 Kfaka Producer의 작동 방식을 설명하는 곳에서 가져온 그림이다.

1.7) 전송 트리거와 drain()을 통한 노드(Broker) 단위 재묶음
위에 Producer생성 부분에서 다음과 같은 설명을 했다.
메인 비즈니스 스레드가 RecordAccumulator라는 메모리 버퍼에 메시지를 차곡차곡 쌓아두면, Sender는 이 버퍼를 지속적으로 확인한다.
Sender 스레드는 RecordAccumulator를 계속 주시하다가, 전송 조건(설정한 batch.size만큼 데이터가 쌓였거나, 최대 대기 시간인 linger.ms에 도달)이 만족된 배치를 꺼낸다.
이때 내부적으로 drain() 이라는 메서드가 아주 영리한 작업을 수행한다.
RecordAccumulator 내부에서 메시지들은 철저하게 "파티션 단위"로 큐(Deque)에 나뉘어 있다.
하지만 Sender 스레드가 네트워크를 통해 쏠 때는 이를 "노드(브로커) 단위"로 다시 묶어낸다.
이게 도대체 무슨 말인가? ㅠㅠ
예를 들어, 0번 파티션의 리더와 2번 파티션의 리더가 둘 다 브로커 1번 서버에 있다고 가정해 봅시다. Sender 스레드는 *"어차피 둘 다 1번 브로커로 가는 거니까, 네트워크 통신 비용을 아끼기 위해 파티션 0번 배치와 파티션 2번 배치를 하나의 TCP 요청으로 묶어서 보내자!"*라고 판단하고 배치를 재조합합니다.
그러니까, 특정 브로커로 보낼거 다른 파티션에 있어도 그냥 한 번에 같이 보낼 수 있게 묶어서 보낸다는 말이다.
1.8) Java NIO와 NetworkClient를 통한 최종 전송
브로커별로 전송할 RecordBatch 리스트가 완성되면, Sender 스레드는 내부의 NetworkClient를 통해 데이터를 실제 네트워크로 쏘아 보낸다.
다만 RecordBatch List가 Sender 의 drain()작업으로 하나의 ProduceRequest를 만들어 Broker Node로 전송한다.
단 하나의 Sender 스레드가 이 Selector를 돌면서 "어떤 브로커 채널이 쓰기 가능(Writable)한지"를 논블로킹으로 감지하여, 대용량의 바이트 배열을 여러 브로커에게 동시에 쏟아붓게 됩니다.
2. Docker 내부에 Producer 파해치고 전송하기
이전에 글 들을 보면 필자가 Mini PC + Docker 환경에 실습 환경을 구축했고,
현재 node1, node2, node3을 순서대로 kafka-1, kafka-2. kafka-3 이라는 브로커 명으로 했다.
이제 이 환경에서 다양한 설정을 통해서 Producer가 실제로 Broker에게 메시지를 보내는 작업을 할 것이다.
우선 필자는 kafka-1에서 이를 하기로 시작했다.
kafka-1 > /tmp 폴더 내부 : my-producer.sh 파일 생성
cat << 'EOF' > my-producer.sh
#!/bin/bash
/opt/kafka/bin/kafka-console-producer.sh \
--bootstrap-server localhost:9092 \
--topic cluster-test \
--command-config /tmp/kafka-logs/custom-producer.properties
EOF
kafka-1 > /tmp/kafka-logs 폴더 내부 : custom-producer.properties 생성
07951ea781ed:/tmp/kafka-logs$ cat << 'EOF' > custom-producer.properties
# ==========================================
# 카프카 프로듀서 핵심 튜닝 옵션 (종합 테스트용)
# ==========================================
# [1] 성능 및 처리량 최적화 (Throughput & Latency)
# ------------------------------------------
# 택배 상자 크기 (64KB: 한 번에 더 많은 데이터를 묶어서 전송)
batch.size=65536
# 택배 상자가 다 안 차도 최대 50ms까지만 기다렸다가 출발
linger.ms=50
# 배치 데이터를 Snappy 알고리즘으로 압축 (네트워크 대역폭 절약)
compression.type=snappy
# [2] 데이터 신뢰성 보장 (Data Durability)
# ------------------------------------------
# 리더와 복제본 브로커 모두에게 저장 완료 응답을 받음 (유실 방지)
acks=all
# 네트워크 오류로 재시도 시, 브로커에 데이터가 중복 저장되는 것을 방지
enable.idempotence=true
# 전송 실패 시 재시도 횟수 (실무에서는 무한에 가깝게 설정)
retries=2147483647
# [3] 메모리 및 네트워크 안정성
# ------------------------------------------
# 프로듀서가 브로커로 보내기 전 데이터를 머금고 있는 총 메모리 공간 (64MB)
buffer.memory=67108864
# 브로커의 응답을 기다리지 않고 연속으로 던질 수 있는 최대 패킷 개수
max.in.flight.requests.per.connection=5
EOF
해당 주소를 참고하면 producer 설정 값을 확인할 수 있다. (kafka 공식 문서 producer config 문서)
여기서 가장 핵심적으로 우리가 알아야 할 것은 무엇인가 싶어서 Gemini에게 요청해서 한번 만들어보았다.
솔직히 필자도 설정이 너무 많다보니 이에 대해서는 Gemini에게 정리를 요청했다.
궁금하면 다음을 열어서 보도록 하자.
카프카 프로듀서 핵심 튜닝 옵션 정리!
성능 및 처리량 최적화 (Throughput & Latency)
1. 카프카의 압도적인 성능을 끌어내는 가장 중요한 옵션 3가지
batch.size (기본값: 16KB) 의미
동일한 파티션으로 보내는 메시지들을 모아두는 택배 상자의 크기(바이트 단위)입니다.
튜닝 포인트는? 트래픽이 많을 때 이 크기를 32KB (32768) 나 64KB (65536) 로 늘리면, 한 번에 더 많은 데이터를 묶어서 보내기 때문에 네트워크 I/O 횟수가 줄어들어 처리량이 극대화됩니다.
linger.ms (기본값: 0) 의미
택배 상자가 다 차지 않았을 때, 출발을 얼마나 기다려줄지 정하는 시간(밀리초)입니다.
튜닝 포인트는? 기본값 0은 데이터가 오자마자 바로 전송을 의미합니다. (적절한 대기 시간 설정이 필요)
만약 이 값을 5에서 100 정도로 주면, 약간의 지연 시간이 발생하는 대신 상자를 꽉꽉 채워서 보낼 수 있어 브로커의 부하를 줄이고 전반적인 성능을 높일 수 있습니다. batch.size와 함께 튜닝합니다.
compression.type (기본값: none) 의미
배치 데이터를 전송할 때 사용할 압축 알고리즘입니다. (gzip, snappy, lz4, zstd) 튜닝 포인트는? 대용량 데이터를 보낼 때 네트워크 대역폭 병목이 발생한다면 압축을 켭니다. 실무에서는 압축 속도와 효율의 밸런스가 좋은 snappy나 lz4를 가장 많이 사용합니다.
2. 데이터 신뢰성 보장 (Data Durability)
데이터를 절대 잃어버리면 안 되는 결제, 로그 기록 등에서 필수적으로 건드리는 옵션입니다.
acks (기본값: 1 또는 all) 의미
프로듀서가 데이터를 보내고 나서, 브로커로부터 잘 받았다는 확인을 어느 수준까지 받을 것인가입니다.
튜닝 포인트는?
- 0: 응답을 안 기다립니다. (가장 빠름, 유실 위험 큼, 센서 데이터 등에 사용)
- 1: 파티션의 리더 브로커가 기록했는지만 확인합니다. (속도와 안전의 타협점)
- all (또는 -1): 리더뿐만 아니라 복제본들까지 전부 기록했는지 확인합니다. (가장 느림, 유실 위험 없음, 금융 및 결제 데이터에 필수)
enable.idempotence (기본값: true) 의미
네트워크 문제로 프로듀서가 재시도를 했을 때, 브로커에 데이터가 중복으로 저장되는 것을 막아주는 멱등성 옵션입니다.
튜닝 포인트는? true로 설정하면 카프카가 내부적으로 시퀀스 번호를 매겨서 중복을 걸러줍니다.
안전한 전송을 원한다면 acks=all과 함께 반드시 켜두어야 합니다.
메모리 및 네트워크 안정성
트래픽 폭주 시 애플리케이션이 뻗지 않도록 방어하는 옵션입니다.
buffer.memory (기본값: 32MB) 의미
프로듀서가 카프카로 데이터를 보내기 전에 잠시 보관하는 전체 메모리 버퍼의 크기입니다.
튜닝 포인트는? 애플리케이션에서 메시지를 생성하는 속도가 카프카로 전송하는 속도보다 빠르면 이 버퍼가 가득 찹니다. 대용량 트래픽 환경에서는 이 값을 64MB 등으로 늘려주어야 합니다.
max.in.flight.requests.per.connection (기본값: 5) 의미
브로커에게 응답을 받지 않은 상태에서, 연속으로 보낼 수 있는 최대 네트워크 요청 개수입니다. 튜닝 포인트: 값을 늘리면 성능이 좋아지지만, 재시도가 발생하면 데이터의 순서가 뒤바뀔 위험이 있습니다. 순서가 중요하다면 5 이하로 두고 멱등성을 켜야 합니다.
실무 요약 가이드 (어떤 상황에 어떻게 튜닝할까요?)
상황 1:
우린 속도가 생명이고, 데이터 1~2개 날아가도 괜찮아! (예: 단순 클릭 로그) 설정: acks=0, linger.ms=0, batch.size=크게
상황 2:
트래픽이 너무 많아서 카프카 서버가 힘들어해! 대역폭 좀 아끼자! 설정: compression.type=snappy, linger.ms=50 (약간 기다림), batch.size=65536
상황 3:
돈이 오가는 데이터라 단 1건도 날아가거나 중복되면 안 돼! (예: 주문/결제) 설정: acks=all, enable.idempotence=true, retries=매우 큰 값
하여간 잘 설정하고 다음과 같이 메시지를 전송했다.
07951ea781ed:/tmp$ ./my-producer.sh
> hello kafka cluster!
> this message is from kafka-1
> testing replication to kafka-2 and 3

그렇게 해서 출력되는 모습을 확인할 수 있다.
사실 처음에 책을 읽어가면서 혼자 정보를 찾아가면서 뭔가 적엇을 때는 아는 듯 했다.
초기에는 아무것도 모르니 빠르게 AI로 정리해서 스윽 훑어보고 으흠! 알겠네! 하고 마무리 지어버렸다.
그런데 무언가 순서가 안맞고 내가 이해를 못한 것 같다는 느낌을 계속 받았다.
그렇다보니 글을 적었어도 계속 글을 수정하면서 추가하던가 제거하는 방식으로 하다보니 더 좋은 내용들도 인터넷에서 찾게되고
이해도 더 잘 하게 되었다.
모든 일이 그런 것 같다.
처음에는 모르고 두려워한다. 그런데 막상 다 하고 나면 별거 아니다. 괜히 두려워했던 내가 민망할 정도이다.
그렇기 때문에 뭐든지 시작을 해보라는 것이 중요하다 생각한다.
카프카 시리즈를 정말 엉터리로 정리하고 인터넷에 올려서 박제해 버렸는데 그 허졉한 과정이 어찌되었든 학습에 긍정적인 영향을 주었다.
결국 하나도 모르는데 아 못하겠다! 가 아닌 아 해보다보면 이해되겠지~ 하는 그러한 어느정도의 낙관이 무엇을 하든 중요하다는 말로 글을 마무리한다.
다음 글에 이어서는 consumer에 대해서 분석하려고 한다.
참고:
https://kafka.apache.org/43/design/design/
https://www.conduktor.io/glossary/kafka-producers
https://docs.confluent.io/platform/current/clients/producer.html
https://dzone.com/articles/take-a-deep-dive-into-kafka-producer-api
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Improvement+Proposals
https://d2.naver.com/helloworld/6560422